公告
页次: 1
#1 2024-04-06 23:25:50
Gentoo 之 Core Scheduling for SMT
说超线程之前,首先要搞清楚什么是cpu,在之前的有一篇文档中对cpu做了简单介绍。
建立在cpu 础之上的内核-聊聊cpu
超线程是针对cpu提出的一种概念与实现,那么超线程的定义是什么?从某文档中摘抄的定义如下:
超线程(hyper-theading)其实就是同时多线程(simultaneous multi-theading),是一项允许一个CPU执行多个控制流的技术。它的原理很简单,就是把一颗CPU当成两颗来用,将一颗具有超线程功能的物理CPU变成两颗逻辑CPU,而逻辑CPU对操作系统来说,跟物理CPU并没有什么区别。因此,操作系统会把工作线程分派给这两颗(逻辑)CPU上去执行,让(多个或单个)应用程序的多个线程,能够同时在同一颗CPU上被执行。注意:两颗逻辑CPU共享单颗物理CPU的所有执行资源。因此,我们可以认为,超线程技术就是对CPU的虚拟化。
比如上述描述,说超线程是让多个线程能同时在同一颗cpu上被执行,其实我觉得这种描述都不够准确,精确的定义应该是:
超线程是同一个时钟周期内一个物理核心上可以执行两个线程或者进的技术。
超线程的定义主要在三个点上,第一个就是同一个时钟周期内,第二个是同一个物理核心,第三个就是两个线程同时执行。
正常情况下,没有超线程技术,以上三个条件是绝对无法满足的。
现在开始去分析超线程的实现过程。
首先,为了让单核cpu发挥更大的作,超线程只是其中一种技术,相关的技术还有很多,比如超标量技术等。
指令的基本执行过程包括:
>取指Fetch)::从存储器取指令,并更新PC
>译码(Decode):指令译码,从寄存器堆读出寄存器的值
>执行(Execute):运算指令:进行算术逻辑运算,访存指令:计算存储器的地址
>访存(Memory):Load指令:从存储器读指令,Store指令:将数据写入寄存器
>回写(Write Back):将数据写入寄存器堆
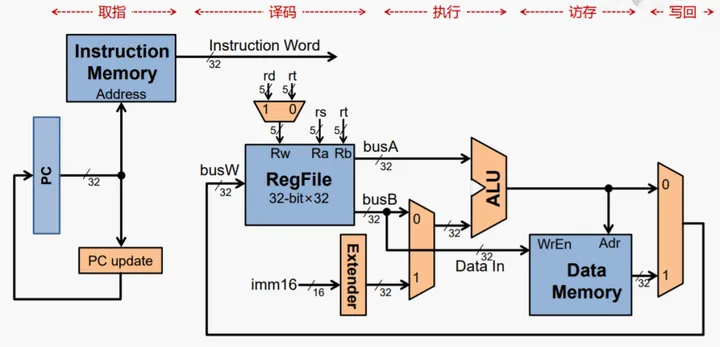
更具体而言,在具体执行过程中,这几个步骤还会区分前端和后端,而且还会有一些相关的技术。
再具体而言,
前端
>前端按顺序取指令和译码,将X86指令翻译成uop。通过分支预测来提前执行最可能的程序路径。
>带有超标量功能的执行引擎每时钟周期最多执行6条uop。带有乱序功能的执行引擎能够重排列uop执行顺序,只要源数据准备好了,即可执行uop。
>顺序提交功能确保最后执行结果,包括碰到的异常,跟源程序顺序一致。
后端
The Out-of-Order Engine
当一个执行流程再等待资源时,比如l2 cache数据,乱序引擎可以把另一个执行流程的uop发射给执行核心。
> Renamer:每时钟周期最多发射4条uop(包括unfused, micro-fused, or macro-fused)。它的工作为:1 重命名uop里的寄存器,解决false dependencies问题。2 分配资源给给uop,例如load or store buffers。3 绑定uop到合适的dispatch port。
>某些uop可以在rename阶段完成,从而不占用之后的执行带宽。
>Micro-fused load 和store操作此时会分解为2条uop,这样就会占用2个发射槽(总共4个)。(没明白为啥之前2条uop融合为一条了现在又分解回2条)
>Scheduler:当uop需要的资源就绪时,即可调度给下一步执行。根据执行单元可用的ports,writeback buses,就绪uop的优先级, 调度器来选择被发射的uop。
>The Execution Core:具有6个ports,每时钟周期最多发射6条uop。指令发射给port执行完成后,需要把数据通过writeback bus写回。每个port有多个不同运算器,这意味着可以有多个不同uop在同一个port里执行,不同uop的写回延时并不相同,但是writeback bus只能独享,这就会造成uop的等待。Sandy Bridge架构尽可能消除改延时,通过把不同类型数据写回到不同的execution stack中来避免。
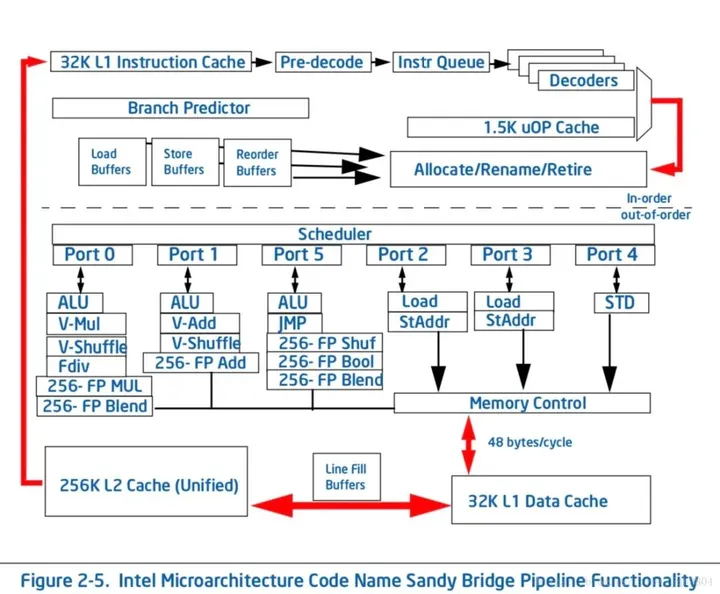
而超线程的实现就是基于以上前端和后端过程的改造与实现。
首先从物理cpu层面上:
从因特尔的cpu开发手册上,我们可以找到超线程的相关实现部分,架构图如下:
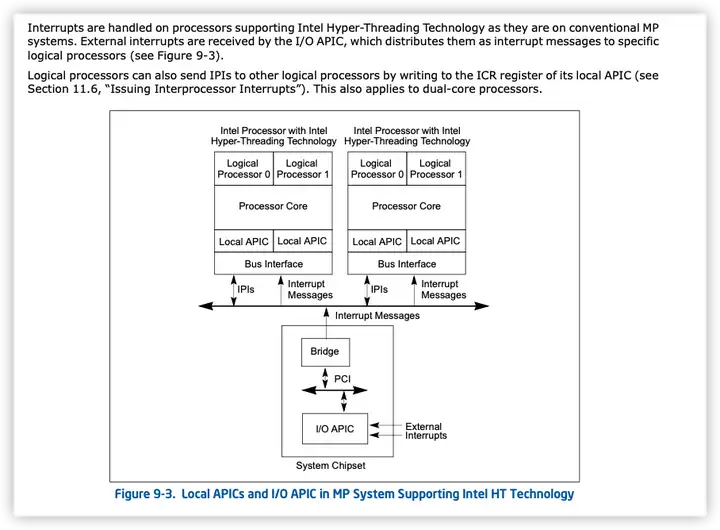
从该架构图上,我们可以看到一个物理核心上有两个逻辑核心,他们有共享的部分也有独立的部分,比如APIC,这个叫做可编程中断控制器,也就是说逻辑核心也是可以自己独立接收中断信号的。
通过该手册,我们可以清楚的了解到超线程中的逻辑核与物理核之间的区别。
The following features are part of he architectural state of logical processors within Intel 64 or IA-32 processors supporting Intel Hyper-Threading Technology. The features can be subdivided into three groups:【以下相关寄存器的作用在文章建立在cpu 基础之上的内核-聊聊cpu中有介绍,但是通过该手册可以了解到,逻辑核心中的大部分寄存器都是独立的,换句话说,在cpu核心中存在双份】
>Duplicated for each logical processor
>Shared by logical processors in a physical processor
>Shared or duplicated, depending on the implementation
>The following features are duplicated for each logical processor:
>General purpose registers (EAX, EBX, ECX, EDX, ESI, EDI, ESP, and EBP)
>Segment registers (CS, DS, SS, ES, FS, and GS)
>EFLAGS and EIP registers. Note that the CS and EIP/RIP registers for each logical processor point to the instruction stream for the thread being executed by the logical processor.
>x87 FPU registers (ST0 through ST7, status word, control word, tag word, data operand pointer, and instruction pointer)
>MMX registers (MM0 through MM7)
>XMM registers (XMM0 through XMM7) and the MXCSR register
>Control registers and system table pointer registers (GDTR, LDTR, IDTR, task register)
>Debug registers (DR0, DR1, DR2, DR3, DR6, DR7) and the debug control MSRs
>Machine check global status (IA32_MCG_STATUS) and machine check capability (IA32_MCG_CAP) MSRs
>Thermal clock modulation and ACPI Power management control MSRs
>Time stamp counter MSRs
>Most of the other MSR registers, including the page attribute table (PAT). See the exceptions below.
>Local APIC registers.
>Additional general purpose registers (R8-R15), XMM registers (XMM8-XMM15), control register,IA32_EFER on Intel 64 processors.
The following features are shared by logical processors:
>Memory type range registers (MTRRs)
Whether the following features are shared or duplicated is implementation-specific:
>IA32_MISC_ENABLE MSR (MSR address 1A0H)
>Machine check architecture (MCA) MSRs (except for the IA32_MCG_STATUS and IA32_MCG_CAP MSRs)
>Performance monitoring control and counter MSRs
其次从指令处理流程上:
整体流程如下
从指令处理过程中,两个逻辑核心都是单独的处理流
前端处理部分
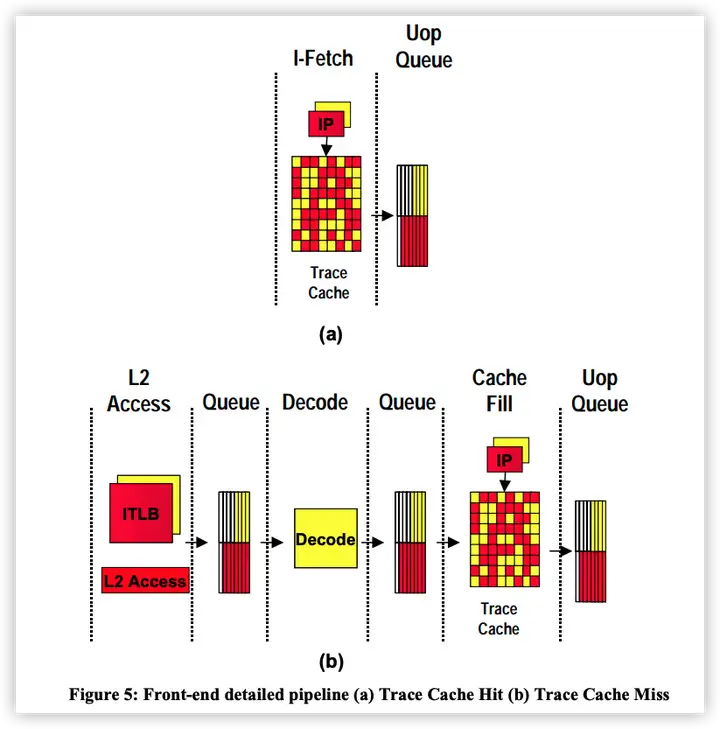
红和黄分属不同的逻辑核心,在有些步骤不作区分,比如解码
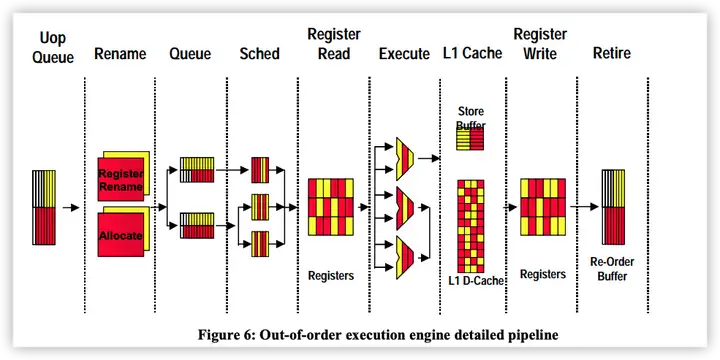
后端部分,在某些流程共享,某些流程独立。
更加具体的可以阅读相关论文
https://www.moreno.marzolla.name/teachi … _art01.pdf
简而言之,超线程的实现是基于物理层面cpu的支持,在一个物理核心中通过改造寄存器的数量以及共享其他资源,从而实现近似于两个物理核心的能力,在操作系统层面可以把线程和进程向上调度,从而更充分的利用资源,提升cpu性能。
离线
页次: 1